1. numpy 배열 생성
# numpy 배열 기본
import numpy as np
v1 = np.array([1, 2, 3, 4])
print(v1)[1 2 3 4]
# 연속되거나 일정한 규칙을 가진 숫자
v1 = np.arange(5)
print(v1)
# 연속되거나 일정한 규칙을 가진 숫자, 데이터 형태 지정
v2 = np.arange(1, 10, 2, dtype=int)
v3 = np.arange(3.5, 10.5, 2, dtype=float)
print(v2)
print(v3)
# 제곱값 생성
v4 = np.arange(1, 10, 2)**2
print(v4)
# 세제곱값 생성
v5 = np.arange(1, 10, 2)**3
print(v5)[0 1 2 3 4]
[1 3 5 7 9]
[3.5 5.5 7.5 9.5]
[1 9 25 49 81]
[1 27 125 343 729]
# 행렬만들기
v1 = np.arange(12)
print(v1)
v2 = v1.reshape(2, 6)
print(v2)
v3 = v1.reshape(2, 6, order='F')
print(v3)[0 1 2 3 4 5 6 7 8 9 10 11]
[[0 1 2 3 4 5]
[6 7 8 9 10 11]]
[[0 2 4 6 8 10]
[1 3 5 7 9 11]]
# 행렬계산
v1 = np.arange(1, 5).reshape(2, 2)
print(np.add(v1, v1)) # 덧셈
print(np.subtract(v1, v1)) # 뺄셈
print(np.multiply(v1, v1)) # 곱셈
print(np.dot(v1, v1)) # 행렬연산[[2 4]
[6 8]]
[[0 0]
[0 0]]
[[1 4]
[9 16]]
[[7 10]
[15 22]]
# 다차원 행렬 만들기
v1 = np.arange(12)
print(v1)
v2 = v1.reshape(2, 3, 2, order='F')
print(v2)[0 1 2 3 4 5 6 7 8 9 10 11]
[[[0 6]
[2 8]
[4 10]]
[[1 7]
[3 9]
[5 11]]]
# 다차원 배열에서 요소의 최대값 및 최소값 변환
v3 = np.arange(3.5, 10.5, 2, dtype=float)
print(v3)
v4 = np.arange(1, 5).reshape(2, 2)
print(v4)
print(np.amax(v3))
print(np.amin(v4))
print(v3.dtype)
print(v4.shape)[3.5 5.5 7.5 9.5]
[[1 2]
[3 4]
9.5
1
float64
(2, 2)
2. pandas 함수 개요
# pandas 함수 불러오기
import pandas as pd
from pandas import Series, DataFrame
# series 설정
a = Series([1, 3, 5, 7])
print(a)
print(a.values)
print(a.index)
# index 변경
a2 = pd.Sereis([1, 3, 5, 7], index = ['a', 'b', 'c', 'd'])
print(a2)0 1
1 3
2 5
3 7
dtype: int64
[1 3 5 7]
RangeIndex(start=0, stop=4, step=1)
a 1
b 3
c 5
d 7
dtype: int64
# index 변경
a2 = pd.Series([1, 3, 5, 7], index=['a', 'b', 'c', 'd'])
a2a 1
b 3
c 5
d 7
dtype: int64
3. DataFrame과 데이터 파일 불러오기
# csv 파일을 pandas DataFrame 형태로 불러오기
df = pd.read_csv('EX_GrapeData.csv')
df
# 엑셀파일을 pandas DataFrame 형태로 불러오기
df = pd.read_excel('EX_GrapeData.xlsx')
df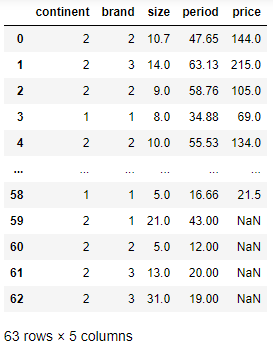
- 한글이 포함되어 있을 경우 인코딩 설정(encoding='euc-kr', 'cp949'', 'utf-8' 등 옵션 설정)
- df = pd.read_csv('EX_GrapeData.csv', encoding='euc-kr')
- df = pd.read_excel('EX_GrapeData.csv', encoding='euc-kr')
4. DataFrame 확인하기
# 데이터 프레임 처음부터 ~개의 행만 불러오기
df.head()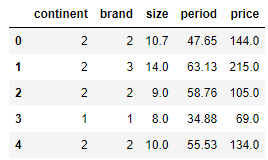
# 데이터 프레임 뒤부터 ~개의 행만 불러오기
df.tail()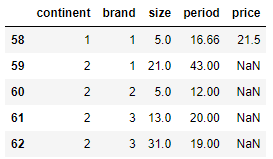
# 1에서 4까지 출력
df[1:5]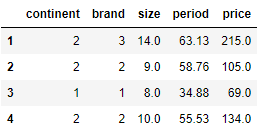
# 처음부터 2까지 출력
df[:3]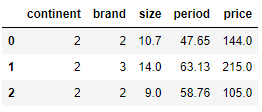
# 60에서 끝까지 출력
df[60:]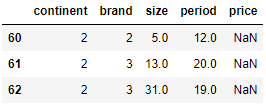
# price 변수(열) 불러오기: series 형태
df['price'] # df.price 로 대체 가능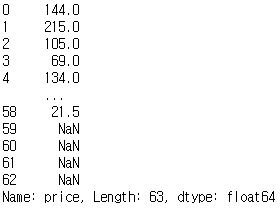
# price 변수(열) 불러오기: DataFrame 형태
df[['price']]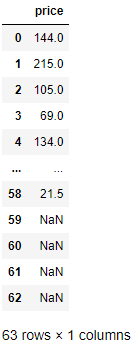
# 0번, 2번, 4번째 열(컬럼)만 출력
df.[df.column[[0, 2, 4]]]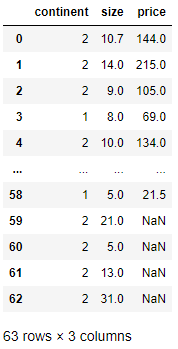
# size부터 price까지 출력
df.loc[:, 'size':'price']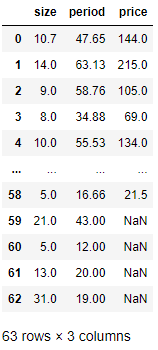
# 1~7행(케이스), 0~2열(변수)만 불러오기
df.iloc[1:7, 0:2]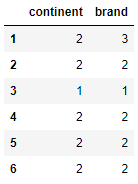
5. 데이터 복사, 추가, 삭제
# 데이터 프레임 전체 복사(백업)
df_columns = df.copy()# 데이터 프레임 전체 복사(백업)
df_columns.columnsIndex(['continent', 'brand', 'size', 'period', 'price'], dtype='object')
# 데이터 프레임 열 필터링
df_columns = df_columns[['size', 'period', 'price']]
df_columns.head()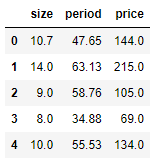
6. 변수이름 변경, 행추가 및 삭제
# 데이터 열(변수) 이름 수정: period -> time
df_columns.rename(columns={'period': 'time'}, inplace=True)
df_columns.columnsIndex(['size', 'time', 'price'], dtype='object')
# size를 time으로 나누어 월별 포도크기로 계산하여 growth 변수 생성
df_columns['growth'] = df.columns['size']/df_columns['time']
df_columns.head()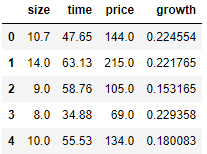
# 특정 변수 삭제 : growth 살제
del df_columns['growth']
7. 데이터 케이스 추출
# 특정 케이스 선택1: 집단선택
df_continent_brand = df[(df['continent'] == 1) & (df['brand'] == 1)]
df_continent_brand.head()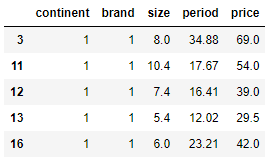
# 특정 케이스 선택2: 기준값 이상 혹은 이하 선택
df_over_size_period=df[(df['size'] >= 10) & (df['period'] >= 30)]
df_over_size_period.head()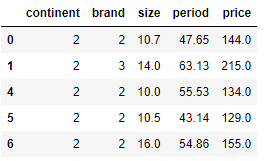
8. 코딩변경
df_columns.head()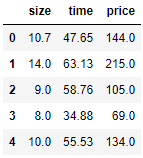
# brand 범주 카운트
df['brnad'].value_counts()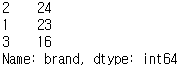
방법 1) replace 사용
# brand 1, 2, 3 집단을 1, 2로 묶기 (1/2 -> 1, 3 ->2)
recode_brand = {"brand" : {1:1, 2:1, 3:2}}df_recode1 = df.replace(recode_brand)
df_recode1.head()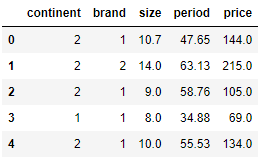
df_recode1['brand'].value_counts()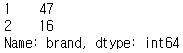
방법2) 함수정의 사용
# 코딩변경 함수 정의
def brand_groups(series) :
if series==1:
return 1
elif series==2:
return 1
elif series==3:
return 2
df['re_brand'] = df['brand'].apply(brand(groups)
df.head()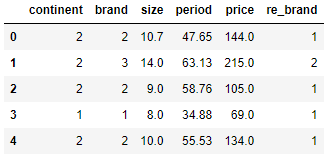
9. pandas와 numpy 전환
# pandas 형태로 데이터 불러와서 확인
import pandas as pd
df = pd.read_csv('EX_GrapeData.csv')
df.head()
# pandas를 numpy로 변환
df_num = df.to_numpy()# numpy를 pandas로 변환 (변수명 미지정)
df_pd = pd.DataFrmae(df_num)# numpy를 pandas로 변환 (변수명 지정)
df_pd2 = pd.DataFrame(data = df_num, columns = ["continent", "brand", "size", "period", "price"])
10. csv 파일로 저장
# 데이터셋명, to_csv("새로운파일명.csv", index=True/False, encoding='utf-8'/'euc'kr', 'cp949')
df.to_csv('new_data.csv', index=False, encoding='utf-8'
'빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사] 빅분기 제6회 실기 시험 합격 후기 (4) | 2023.06.25 |
|---|---|
| [빅데이터분석기사] 작업형 1유형 연습문제 #3 (0) | 2023.06.01 |
| [빅데이터분석기사] 제3회 실기 시험 불합격 후기 (0) | 2022.05.17 |
| [빅데이터분석기사] 제3회 빅데이터분석기사 필기 시험 후기 (1) | 2021.10.02 |