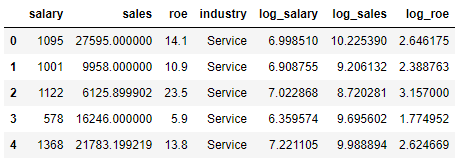
자동차 시장 세분화 - 자동차 회사는 새로운 전략을 수립하기 위해 4개의 시장으로 세분화했습니다. - 기존 고객 분류 자료를 바탕으로 신규 고객이 어떤 분류에 속할지 예측해주세요! - 예측할 값(y) : "Segmentation" (1, 2, 3, 4) - 평가 : Macro f1-score - data : train.csv, test.csv - 제출형식 답안 제출 참고 - 아래 코드 예측변수와 수험번호를 개인별로 변경하여 활용 - pd.DataFrame({'ID' : test.ID, 'Segmentation' : pred})).to_csv('003000000.csv', index=False) 노트북 구분 - basic : 수치형 데이터만 활용 -> 학습 및 test 데이터 예측 - intermediat..