반응형
1. 데이터 불러오기 및 확인
# 분석데이터(선거행동) 불러와서 데이터 확인
import pandas as pd
data = pd.read_csv("Fvote.csv', encoding='utf-8')
data.head()
data.describe()
data.hist(figsize=(20, 10))

2. 특성(X)과 레이블(y) 나누기
# 특성 변수와 레이블 변수 나누기
X = data.loc[:, 'gender_female':'score_intention']
y = data[['vote']]# 특성변수와 레이블 변수 행열확인
print(X.shape)
print(y.shape)(211, 13)
(211, 1)
3. train-test 데이터셋 나누기
# 학습용 데이터(train)와 테스트용 데이터(test) 구분을 위한 라이브러리 불러오기
# 레이블이 범주형일 경우 straity 옵션 추천
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)# 학습데이터와 테스트데이터의 0/1 비율이 유사한지 평균으로 확인(stratify 옵션 적용 시 유사)
print(y_train.mean())
print(y_test.mean())vote 0.708861
dtype: float64
vote 0.716981
dtype: float64
4. 연속형 특성의 정규화
가. Min-Max 정규화
# 특성치(X)의 단위 정규화를 위한 라이브러리 불러오기(min-max)
from sklearn.preprocessing import MinMaxScaler
scaler_minmax = MinMaxScaler()# min-max 방법으로 정규화
# 주의! : fit은 학습데이터로 해야 나중에 test 데이터 정규화 시 train 데이터의 최대-최소 기준이 적용됨
scaler_minmax.fit(X_train)
X_scaled_minmax_train = scaler_minmax.transform(X_train)# min-max 방법으로 정규화한 데이터의 기술통계량 확인
pd.DataFrame(X_scaled_minmax_train).decribe()
# test 데이터에도 정규화 적용 및 데이터 확인 : min-max 방법
X_scaled_minmax_test = scaler_minmax.transform(X_test)
pd.DateFrame(X_sclaed_minmax_test).describe()
나. Standardization 정규화
# 특성치(X)의 단위 정규화를 위한 라이브러리 불러오기(standard)
from sklearn.preprocessing import StandardScaler
scaler_standard = StandardScaler()# standard 방법으로 정규화
# 주의! : fit은 학습데이터로 해야 나중에 test 데이터 정규화 시 train 데이터의 표준화(평균, 표준편차) 기준이 적용됨
scaler_standard.fit(X_train)
X_scaled_standard_train = scaler_standard.transform(X_train)# standard 방법으로 정규화한 데이터의 기술통계량 확인
pd.DataFrame(X_scaled_standard_train).describe()
# test 데이터에도 정규화 적용 및 데이터 확인 : standard 방법
X_scaled_standard_test = scaler_standard.transform(X_test)
pd.DataFrame(X_scaled_standard_test). describe()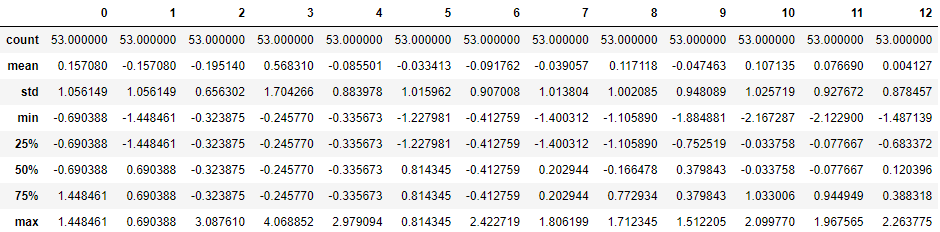
5. 모델 학습
# ML 알고리즘 모듈 불러오기 및 학습데이터에 적용(LogisticRegression)
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()가. Min-Max 정규화 데이터 적용결과
# 훈련데이터의 정확도(accuracy) 확인
model.fit(X_scaled_minmax_train, y_train)
pred.train = model.predict(X_scaled_minmax_train)
model.score(X_sclaed_minmax_train, y_train)0.7278481012658228
# 테스트 데이터의 정확도
pred_test = model.predict(X_scaled_minmax_test)
model.score(X_scaled_minmax_test, y_test)0.7169811320754716
# 학습데이터의 혼동행렬 보기(정분류, 오분류 교차표)
from sklearn.metrics import confusion_matrix
confusion_train = confusion_matrix(y_train, pred_train)
print("훈련데이터 오차행렬: \n", confusion_train)훈련데이터 오차행렬:
[[ 9 37]
[ 6 106]]
# 테스트데이터의 혼동행렬 보기(정분류, 오분류 교차표)
confusion_test = confusion_matrix(y_test, pred_test)
print("테스트데이터 오차행렬:\n", confusion_test)테스트데이터 오차행렬:
[[ 2 13]
[2 36]]
나. Standardize 정규화 데이터 적용결과
# 훈련데이터의 정확도(accuracy) 확인
model.fit(X_scaled_standard_train, y_train)
pred_train = model.predict(X_scaled_standard_train)
model.score(X_scaled_standard_train, y_train)0.6792452830188679
# 학습데이터의 혼동행렬 보기(정분류, 오분류 교차표)
from sklearn.metrics import confusion_matrix
confusion_train = confusion_matrix(y_train, pred_train)
print("훈련데이터 오차행렬: \n", confusion_train)훈련데이터 오차행렬:
[[ 12 34]
[ 7 105]]
# 테스트데이터의 혼동행렬 보기(정분류, 오분류 교차표)
confusion_test = confusion_matrix(y_test, pred_test)
print("테스트데이터 오차행렬: \n", confusion_test)테스트데이터 오차행렬:
[[ 3 12]
[ 5 33]]
반응형
'빅데이터분석기사 > 코드' 카테고리의 다른 글
| [빅데이터분석기사] 모델평가 (0) | 2022.06.17 |
|---|---|
| [빅데이터분석기사] 모델훈련과 튜닝 (0) | 2022.06.14 |
| [빅데이터분석기사] 데이터셋 분할과 모델검증 (0) | 2022.06.12 |
| [빅데이터분석기사] 범주변수의 변환(one-hot-encoding) (0) | 2022.06.11 |
| [빅데이터분석기사] 데이터탐색과 데이터정제 실습 (2) (0) | 2022.06.07 |