1. 데이터 불러오기 및 데이터셋 분할
# 분석 데이터 불러오기
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
data = pd.read_csv('Fvote.csv', encoding='utf-8')# 특성치와 레이블 데이터셋 구분
X = data[data.columns[1:13]]
y = data[['vote']]# 훈련 데이터, 테스트 데이터 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
2. Grid Search
# 그리드서치를 위한 라이브러리 및 탐색 하이퍼파라미터 설정
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100]}# LogisticRegression 알고리즘 적용
from sklearn.linear_model import LogisticRegression# 그리드서치를 로지스틱 모델에 적용하여 훈련데이터 학습
# 교차검증(cv) 5 설정, 훈련데이터 정확도 결과 제시하기(True)
grid_search = GridSearchCV(LogisticRegression(), param_grid, cv=5, return_train_score=True)
grid_search.fit(X_train, y_train)GridSearch(cv=5, estimator=LogisticRegression(),
param_grid={'C': [0.001, 0.01, 0.1, 1, 10, 100]},
return_train_score=True)
# 정확도가 가장 높은 하이퍼파라미터(C) 및 정확도 제시
print("Best Parameter: {}".format(grid_search.best_params_))
print("Best Cross-validity Score: {:.3f}".format(grid_search.best_score_))Best Parameter: {'C': 10}
Best Cross-validity Score: 0.727
# 테스트 데이터에 적용(C=10), 정확도 결과
print("Test set Score: {:.3f}".format(grid_search.score(X_test, y_test)))Test set Score: 0.679
# 그리드서치 하이퍼파라미터별 상세 결과값
result_grid = pd.DataFrame(grid_search.cv_results_)
result_grid
# 하이퍼파라미터(C)값에 따른 훈련데이터와 테스트데이터의 정확도(accuracy) 그래프
import matplotlib.pyplot as plt
plt.plot(result_grid['param_C'], result_grid['mean_train_score'], label="Train")
plt.plot(result_grid['param_C'], result_grid['mean_test_score'], label="Test")
plt.legend()
3. Random Search
# 랜덤서치를 위한 라이브러리 및 탐색 하이퍼파라미터 설정
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs={'C': randint(low=0.001, high=100)}# LogisticRegression 알고리즘 적용
from sklearn.linear_model import LogisticRegression# 랜덤서치를 로지스틱 모델에 적용하여 훈련데이터 학습
# 교차검증(cv) 5 설정, 훈련데이터 정확도 결과 제시하기(True)
random_search=RandomizedSearchCV(LogisticRegression(),
param_distributions=param_distribs, cv=5,
# n_iter=100, 랜덤횟수 디폴트=10
return_train_score=True)
random_search.fit(X_train, y_train)RandomizedSearchCV(cv=5, estimator=LogisticRegression(),
param_distributions={'C': <scipy.stats._distn_infrastructure.rv_frozen object at 0x000001F9F0268EE0>}
return_train_score=True)
# 정확도가 가장 높은 하이퍼파라미터(C) 및 정확도 제시
print("Best Parameter: {}".format(random_search.best_params_))
print("Best Cross-validity Score: {:.3f}".format(random_search.best_score_))Best Parameter: {'C': 67}
Best Cross-validity Score: 0.727
# 테스트 데이터에 최적 탐색 하이퍼파라미터 적용 정확도 결과
print("Test set Score: {:.3f}".format(random_search.score(X_test, y_test)))Test set Score: 0.679
# 랜덤서치 하이퍼파라미터별 상세 결과값
result_random = random_search.cv_results_
pd.DataFrame(result_random)# 하이퍼파라미터(C)값에 따른 훈련데이터와 테스트데이터의 정확도(accuracy) 그래프
import matplotlib.pyplot as plt
plt.plot(result_random['param_C'], result_random['mean_train_score'], label="Train")
plt.plot(result_random['param_C'], result_random['mean_test_score'], label="Test")
plt.legend()
4. 모델평가
# 모델탐색 결과, 최적의 하이퍼파라미터 결정 및 적용(예: C=10)
Final_model = LogisticRegression(C=10)
Final_model.fit(X_train, y_train)LogisticRegression(C=10)
# 훈련데이터의 정확도(accuracy) 결과
pred_train = Final_model.predict(X_train)
Final_model.score(X_train, y_train)0.740506329113924
# 테스트데이터의 정확도(accuracy) 결과
pred_test = Final_model.predict(X_test)
Final_model.score(X_test, y_test)0.6792452830188679
# 훈련데이터의 혼동행렬
from sklearn.metrics import confusion_matrix
confusion_train = confusion_matrix(y_train, pred_train)
print("훈련데이터 오차행렬:\n", confusion_train)훈련데이터 오차행렬:
[[ 12 34]
[ 7 105]]
# 훈련데이터의 분류 모델 평가 결과
from sklearn.metrics improt classification_report
cfreport_train = classification_report(y_train, pred_train)
print("분류예측 레포트:\n", cfreport_train)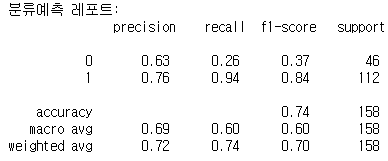
# 테스트데이터의 정확도(accuracy) 결과
confusion_test = confusion_matrix(y_test, pred_test)
print("테스트데이터 오차행렬:\n", confusion_test)테스트데이터 오차행렬:
[[ 3 12]
[ 5 33]]
# 테스트데이터의 분류 모델 평가 결과
from sklearn.metrics import classification_report
cfreport_test = classification_report(y_test, pred_test)
print("분류예측 레포트:\n", cfreport_test)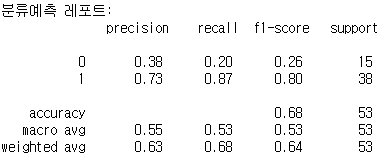
# ROC 계산을 위한 라이브러리 및 산출식
from sklearn.metrics import roc_curve, auc
from sklearn import metrics
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, Final_model.decision_function(X_test))
roc_auc = metrics.roc_auc_score(y_test, Final_model.decision_function(X_test))
roc_auc0.6350877192982456
# ROC Curve 작성
import matplotlib.pyplot as plt
plt.title('Receiver Operating Characteristic')
plt.xlabel('False Positive Rate(1 - Specificity)')
plt.ylabel('True Positive Rate(Sensitivity)')
plt.plot(false_positive_rate, true_positive_rate, 'b', label='Model (AUC = %0.2f)'%roc_auc)
plt.plot([0, 1], [1, 1], 'y--')
plt.plot([0, 1], [0, 1], 'r--')
plt.legend(loc = 'lower right')
plt.show()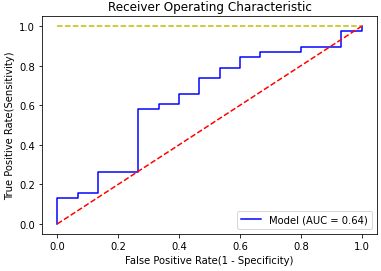
함께 보면 좋은 글
[빅데이터분석기사] 모델훈련과 튜닝
1. 데이터 불러오기 및 데이터셋 분할 # 분석 데이터 불러오기 import warning warning.filterwarnings("ignore") import pandas as pd data = pd.read_csv('Fvote.csv', encoding='utf-8') # 특성치와 레이블 데..
it-utopia.tistory.com
[빅데이터분석기사] 데이터 스케일링
1. 데이터 불러오기 및 확인 # 분석데이터(선거행동) 불러와서 데이터 확인 import pandas as pd data = pd.read_csv("Fvote.csv', encoding='utf-8') data.head() data.describe() data.hist(figsize=(20, 10))..
it-utopia.tistory.com
[빅데이터분석기사] 데이터셋 분할과 모델검증
1. 특성치(X), 레이블(y) 나누기 # 데이터셋 불러오기 및 확인 import warnings warning.filterwarnings("ignore") import pandas as pd data = pd.read_csv('Fvote.csv', encoding='utf-8') data.head() # 특성..
it-utopia.tistory.com
[빅데이터분석기사] 데이터탐색과 데이터정제 실습 (2)
[빅데이터분석기사] 데이터탐색과 데이터정제 실습 (2)
4. 변수 변환 4-1. log 변환 import numpy as np data['log_salary'] = np.log(data['salary']) data['log_sales'] = np.log(data['sales']) data['log_roe'] = np.log(data['roe']) data.head() data.hist(bins=..
it-utopia.tistory.com
[빅데이터분석기사] 데이터탐색과 데이터정제 실습 (1)
[빅데이터분석기사] 데이터탐색과 데이터정제 실습 (1)
1. 데이터탐색: 단변량 import pandas as pd data=pd.read_csv('Ex_CEOSalary.csv', encoding='utf-8') data.info() data.head() 1-1. 범주형 자료의 탐색 data['industry'].value_counts() data['industry'] =..
it-utopia.tistory.com
'빅데이터분석기사 > 코드' 카테고리의 다른 글
| [빅데이터분석기사] 작업형 1유형 예시문제 풀이 (0) | 2023.05.24 |
|---|---|
| [빅데이터분석기사] 6회 실기시험부터 적용되는 작업형 3유형 풀이 (1) | 2023.05.23 |
| [빅데이터분석기사] 모델훈련과 튜닝 (0) | 2022.06.14 |
| [빅데이터분석기사] 데이터 스케일링 (0) | 2022.06.13 |
| [빅데이터분석기사] 데이터셋 분할과 모델검증 (0) | 2022.06.12 |