반응형
1. 데이터탐색: 단변량
import pandas as pd
data=pd.read_csv('Ex_CEOSalary.csv', encoding='utf-8')data.info()
data.head()
1-1. 범주형 자료의 탐색
data['industry'].value_counts()data['industry'] = data['industry'].replace([1, 2, 3, 4], ['Service', 'IT', 'Finance', 'Others'])
data['industry'].value_counts()%matplotlib inline
data['industry'].value_counts().plot(kind="pie")data['industry'].value_counts().plot(kind="bar")
1-2. 연속형 자료의 탐색
data.info()data.describe()data.skew()data.kurtosis()
※ pandas 제공 기술통계 함수
- count : N/A 값을 제외한 값의 수를 반환
- describe : 시리즈 혹은 데이터프레임의 각 열에 대한 기술 통계
- min, max : 최소, 최대값
- argmin, argmax : 최소, 최대값을 갖고 있는 색인 위치 반환
- idxmin, idxmanx: 최소, 최대값을 갖고 있는 색인의 값 반환
- quantile : 0부터 1까지의 분위수 계산
- sum : 합
- mean : 평균
- median : 중위값
- mad : 평균값에서 절대 평균편차
- var : 표본 분산
- std : 표본 정규분산
- skew : 표본 비대칭도
- kurt : 표본 첨도
- cumsum : 누적 합
- cummin, cummax : 누적 최소값, 누적 최대값
- cumprod : 누적 곱
- diff : 1차 산술차(시계열 데이터 사용 시 유용)
- pct_change : 퍼센트 변화율 계산
- corr : 데이터프레임의 모든 변수 간 상관관계를 계산하여 반환
- cov : 데이터프레임의 모든 변수 간 공분산을 계산하여 반환
import matplotlib.pyplot as plt
data.hist(bins=50, figsize=(20, 15))
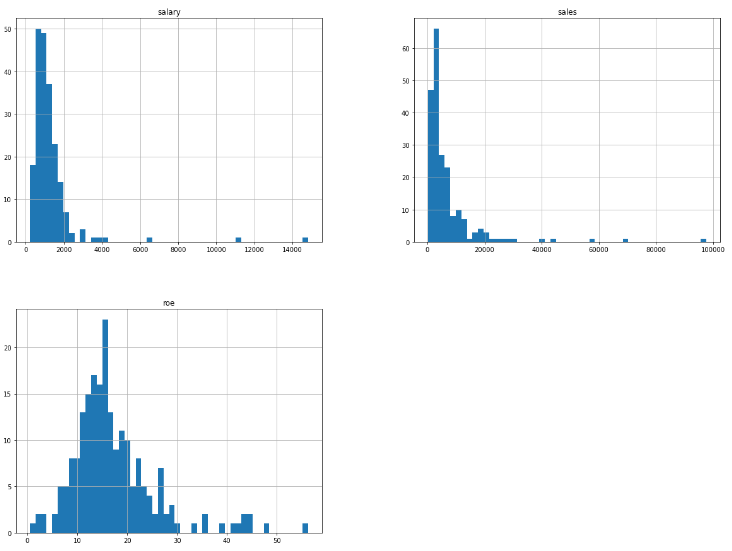
data['salary'].hist(bins=50, figsize=(20, 15))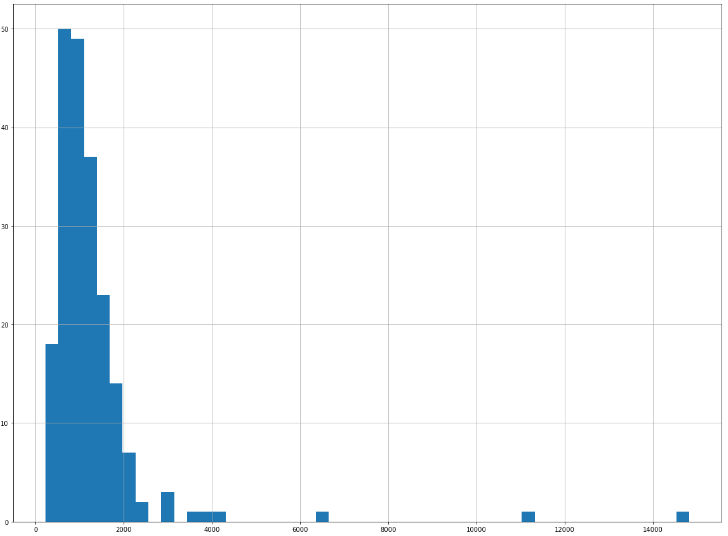
2. 데이터탐색: 이변량
data.corr()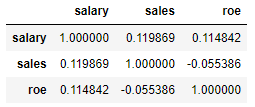
data.corr(method="pearson")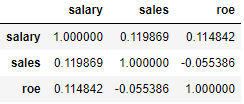
data.corr(method="spearman")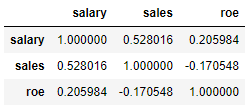
data.corr(method="kendall")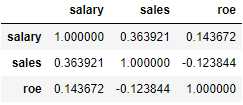
import matplotlib.pyplot as plt
plt.scatter(data['sales'], data['salary'], alpha=0.5)
plt.show()
plt.scatter(data['roe'], data['salary'], alpha=0.5)
plt.show()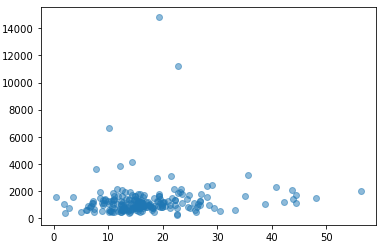
data.groupby('industry')[['salary']].describe()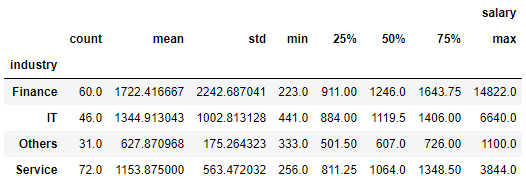
3. 이상치 처리
data.boxplot(column='salary', return_type='both')
data.boxplot(column='sales', return_type='both')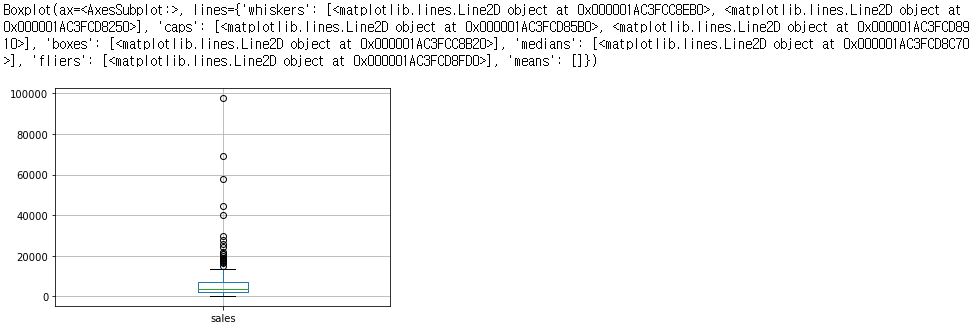
data.boxplot(column='roe', return_type='both')
3-1. salary 변수 이상치 처리
Q1_salary = data['salary'].quantile(q=0.25)
Q3_salary = data['salary'].quantile(q=0.75)
IQR_salary = Q3_salary-Q1_salary
IQR_salary671.0
data_IQR=data[(data['salary']<Q3_salary+IQR_salary*1.5)&(data['salary']>Q1_salary-IQR_salary*1.5)]data_IQR['salary'].hist()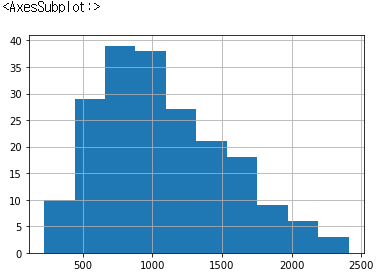
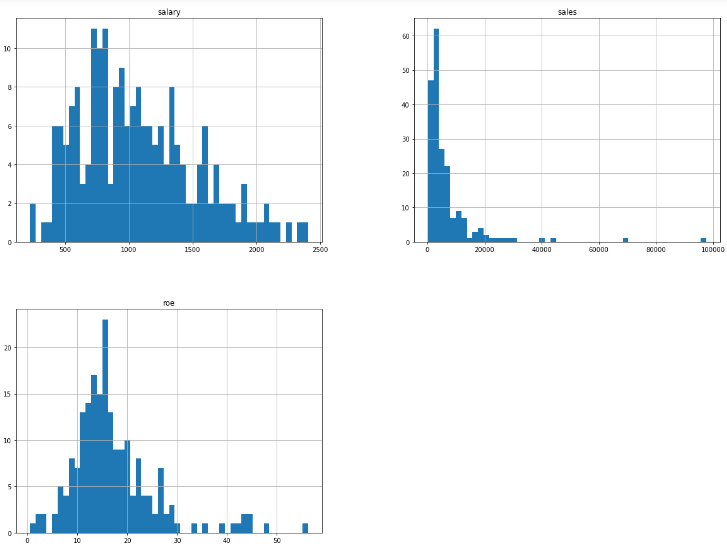
data_IQR.hist(bins=50, figsize=(20, 15))
data_IQR.corr()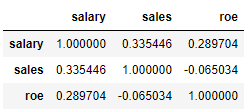
import matplotlib.pyplot as plt
plt.scatter(data_IQR['sales'], data_IQR['saraly'], alpha=0.5)
plt.show()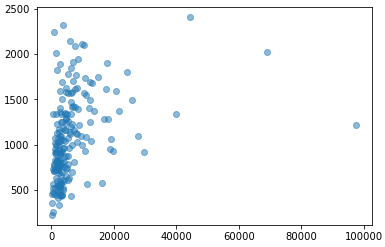
plt.scatter(data_IQR['roe'], data_IQR['salary'], alpha=0.5)
plt.show()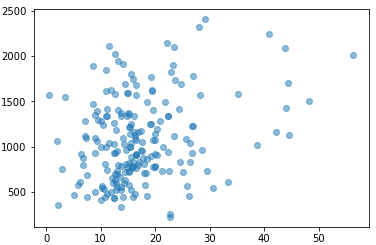
3-2. sales 변수 이상치 처리
Q1_sales = data['sales'].quantile(q=0.25)
Q3_sales = data['sales'].quantile(q=0.75)
IQR_sales = Q3_sales-Q1_sales
IQR_sales4966.6999511718695
data_IQR=data[(data['sales']<Q3_sales+IQR_sales*1.5)&(data['sales']>Q1_sales-IQR_sales*1.5)&
(data['salary']<Q3_salary+IQR_salary*1.5)&(data['salary']>Q1_salary-IQR_salary*1.5)]data_IQR['sales'].hist()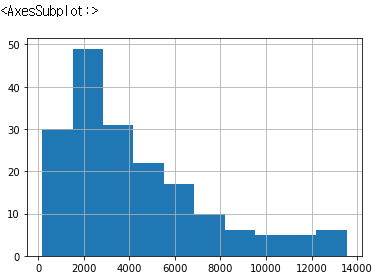
data_IQR.hist(bins=50, figsize=(20, 15))
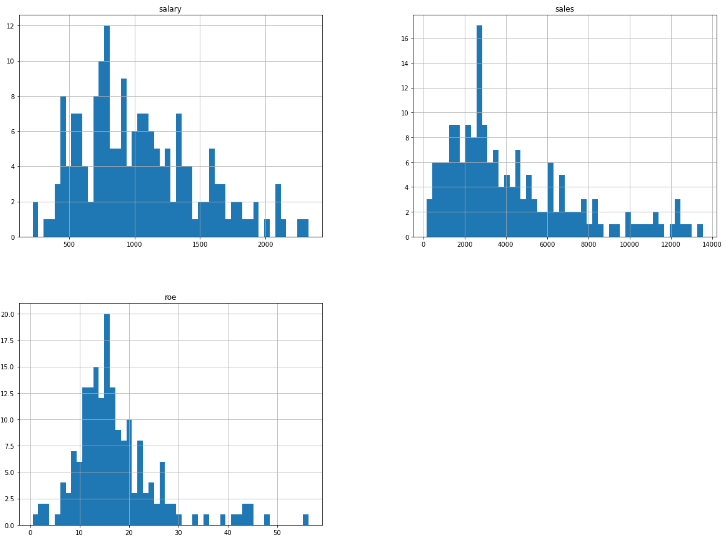
data_IQR.corr()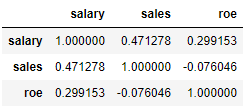
반응형
'빅데이터분석기사 > 코드' 카테고리의 다른 글
| [빅데이터분석기사] 범주변수의 변환(one-hot-encoding) (0) | 2022.06.11 |
|---|---|
| [빅데이터분석기사] 데이터탐색과 데이터정제 실습 (2) (0) | 2022.06.07 |
| [빅데이터분석기사] 파이썬 데이터 정제 실습 (0) | 2022.06.03 |
| [빅데이터분석기사] 파이썬(Python) 기초 - 자료형 if문 반복문 (0) | 2022.05.31 |
| [빅데이터분석기사] 파이썬 머신러닝(ML) 기본 틀 맛보기 (0) | 2021.12.03 |