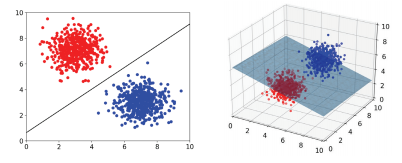
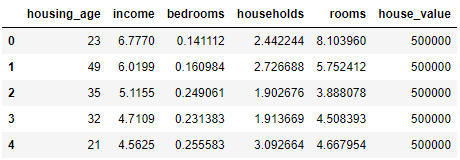
1. 데이터탐색: 단변량 import pandas as pd data=pd.read_csv('Ex_CEOSalary.csv', encoding='utf-8') data.info() data.head() 1-1. 범주형 자료의 탐색 data['industry'].value_counts() data['industry'] = data['industry'].replace([1, 2, 3, 4], ['Service', 'IT', 'Finance', 'Others']) data['industry'].value_counts() %matplotlib inline data['industry'].value_counts().plot(kind="pie") data['industry'].value_counts().plot(ki..