주성분분석
여러 특성(feature) 가운데 대표 특성을 찾아 분석하는 방식으로, 대표 특성의 선별은 자료의 차원을 고차원에서 하위 차원으로 축소하는(차원축소) 기법을 활용한다. 차원축소기법에 대한 이해가 주성분 분석의 시작이자 끝이며 여기서는 2차원을 1차원으로 축소하는 범위로 한정해 설명하고자 한다.

분산, 차원축소를 위한 주성분의 선택 기준
위 그림과 같이 차원축소를 위한 정사영의 시작은 무엇을 기준으로 선택되는 것일까? 선택에 따라 데이터의 실제 특성을 보존할 수도 있고 반대로 잃을 수도 있다. C1을 참고하면 우린 자연스럽게 데이터 간 거리가 가장 큰 쪽이 가장 강력한 데이터 변화 방향이란 사실을 직관적으로 이해할 수 있다. 결국 주성분 선택에 있어 최초로 고려되는 요소는 분산이 가장 큰 하나의 데이터 선(2차원으로 축소시는 면)이 된다.
직교(Orthogonality), 그 다음 주성분을 찾는 기준
그렇다면 다음 주성분은 어떻게 찾는 것일까? 두 번째 주성분은 첫 번째 주성분과 '직교'하는 또 하나의 선(또는 면)이다. 다음 주성분은 첫 번째로 분산이 큰 쪽이 선택된다. 두 선이 직교하고 있다면 하나의 선과 다른 하나의 선은 서로 가장 독립적인 상태라고 말할 수 있는 상태다. 이를 내적(Inner Product)이 0인 상태라고 하는데, 좌표상에 두 선이 수직(90도)을 이루며 교차함을 뜻한다.
A라는 선형이 180도 회전하게 되더라도 그 방향벡터의 크기와 방향은 동일하기 때문에, 서로 가장 닮지 않는 다른 하나의 선형은 A선형과의 관계가 수직(90도)이다. 가령 xi의 값이 증가함에 따라 yi값이 증가한다면 우리는 그 관계가 양의 상관관계로 '우상향'하는 방향임을 알 수 있다. 반대로 xi값은 증가하는데 yi값이 감소하면 '우하향'한다는 사실도 함께 확인 가능하다. 즉, xi가 고정일 때 yi값이 완전 반대의 방향을 갖는 경우의 선형의 결과는 결과적으로 90도가 되는 것이다.
차원축소의 3가지 순기능
우리가 주성분 분석을 사용하는 이유는 데이터가 가진 특성의 수가 지나치게 많을 때, 그 수를 적절하게 줄임으로써 얻는 이점이 있기 때문이다. 특성의 수를 줄일 때 우리는 크게 3가지 순기능을 기대해 볼 수 있다.
먼저 차원이 낮아지면 대상에 대한 이해가 보다 쉬워지게 된다. 공간보다는 면, 면보다는 선, 선보다는 점을 이해하는 것이 보다 용이한 것과 같은 맥락이다. 다음으로 얻을 수 있는 장점은 연산속도가 개선된다는 점이다. 분산값을 유지하면서 정보의 크기 자체를 줄이기 때문에, 데이터의 특성을 훼손시키지 않고도 보다 빠른 연산을 기대할 수 있게 된다.
마지막으로 차원축소는 '차원의 저주'를 해결하는 열쇠가 된다. 선보다는 면, 면보다는 육면체에 데이터가 위치할 공간이 훨씬 크다는 사실은 누구나 쉽게 이해할 수 있을 것이다. 만약 데이터의 양이 동일한 경우에 보다 상위 차원 속에 데이터를 위치시키면 어떨까. 그 결과는 아래 그림처럼 서로 간의 거리가 더욱 멀어진 모습으로 보여질 것이다.
이런 경우에 발생하는 문제를 차원의 저주라고 한다. 차원 증가에 따라 요구되는 데이터의 양이 기하급수적으로 늘어나기 때문에 우리는 차원축소를 통해 이와 같은 문제를 해결할 수 있다. 높아진 차원을 고려한 데이터 증량이 없다면 우리는 고차원의 데이터를 학습시키는 과정에서 '과적합(overfitting)'의 문제를 겪을 것이다. 차원축소는 이처럼 데이터가 부족한 상태에서 과적합을 예방하는 전처리 기법으로 가능하게 된다.
분석 연습
위스콘신 암센터 569명의 유방암 진료 환자 샘플 데이터를 PCA에 활용하였다. 암 진단에 필요한 속성정보와 양성(Benign)/악성(malignant) 진단 결과로 분류된 환자 데이터이다. 해당 데이터 세트를 검토하여 유방암 진단에 설명력이 높은 주성분들을 찾아본다.
1) Breast Cancer Wisconsin Diagnostic 데이터 세트 구성의 총 속성을 확인한다.
2) 569명의 환자를 기준으로 속성 정보를 표기하는 데이터 프레임을 작성하고 데이터값들을 확인한다.
3) 양성/악성 정보 바탕의 진단 결과를 속성별 관계로 플로팅하여 양성 진단과 악성 진단에 대한 환자 분포의 분명한 차이를 시각적으로 확인한다. 시각화된 그래프만을 가지고도 양성인지 악성인지를 판단할 때, 각 속성값이 분명한 차이를 보였다는 사실을 알 수 있다.
4) 다음으로 데이터 표준화 또는 정규화 작업이 필요하다. 속성마다 데이터값의 범위가 다르므로 이를 주성분 선별 전에 전처리해야 각 속성의 영향도를 같은 선상에서 비교할 수 있다. 여기서 표준화는 사이킷런(scikit-learn) 전처리 모듈 가운데 Standard Scaler 함수를 사용해 수행했다.
4-1) 사이킷런(scikit-learn) 라이브러리 PCA모듈을 활용해 공분산(Covariance)과 상관계수를 구한다.
※ 상관분석의 '공분산' 참고
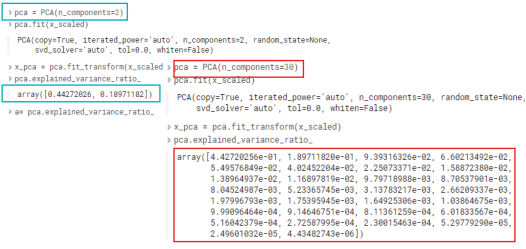
PCA 함수에서 n_component가 설정하는 정수가 차원을 설정하는 값이다. <악성과 양성 환자 분포> 그림에서 확인했듯, 두 속성별 관계를 2차원 환자 산점도로 표현할 수 있었다. 속성 하나가 곧 하나의 차원이며 변수이므로, 여기서는 차원설정값을 30으로 설정하여 PCA함수에서 서른 가지 특성에 대한 공분산을 반환받은 것이다.
데이터 표준화와 정규화의 차이
데이터전처리를 하기 위해 흔히 표준화와 정규화라는 방법을 많이 사용하게 된다. 혼동하기 쉬운 용어이나 의미와 사용목적이 차이가 있으므로 적정한 전처리 방법을 선택해 분석해야 한다.
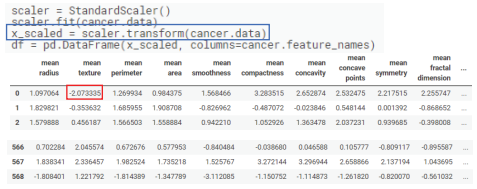
4-2) 각 속성별 Scale을 통일하는 표준화 과정을 수행한다. transform 함수로 데이터의 전체를 표준화를 진행했다.
※ 상관분석 '상관계수' 참고
4-3) 전체 데이터를 표준화했으니 주성분으로써 기능을 할 수 있는 속성 간 비교가 가능하다. 상관계수의 순위 막대그래프는 6가지 주성분을 시각화한 Bar 차트이다. 결과적으로 30개 변수 중 상관관계가 높은 변수끼리 선형 결합을 했을 때 전체 변화를 설명하는 데 유력한 변수가 6가지란 의미이다.
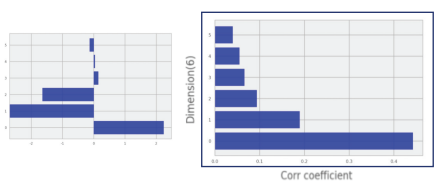
PCA 분석을 수행하기 전에 상관계수를 통한 데이터 표준화가 필요하다는 사실 이해와 더불어 전처리 이후 가장 계숫값이 높은 속성별로 서열을 확인하여 환자 양성 및 악성 진단에 대한 영향력이 큰 최적의 차원 수를 확인하였다.
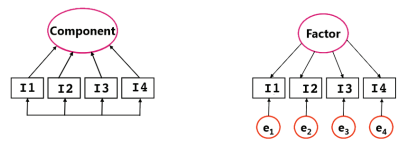
주성분분석과 혼동하지 말자, 요인분석(Factor Analysis)
결과에 대한 결정적인 인자(원인요소)를 찾아내는 방법이다. 주성분분석과 차이를 대조하여 이해하는 것이 좋은데 그 차이를 이해하기 위해서 먼저 분산을 다시 확인한다.

주성분(Principle Components)과 요인(Factor)의 차이
주성분분석에서 차원축소를 위해 사용한 분산은 공분산이었다. 여러 변수 간의 상관관계를 공통의 분산으로 밝히고 일정한 기준(=상관계수)으로 우선순위를 설정하는 과정, 즉 종속변수 y에 영향도가 높은 1개 이상의 독립변수 xn을 찾는 것이 바로 주성분분석이다. (x1, ..., xn의 총합은 1이다. 여기서 1은 완전한 설명력으로 이해해도 좋다.)
이와 달리 요인분석에서 Factor를 찾기 위해서 고유분산을 이용한다. 예를 들어 국어, 영어, 수학 점수를 통해 '언어능력'을 측정한다는 가정에서, 각 점수에 영향을 끼친 고유한 원인을 찾는 과정이 요인분석이다. 각 변수마다 독립적인 특성을 확인해야 하므로 고유분산을 사용한다.
함께 보면 좋은 글
[빅데이터분석기사] 회귀분석(Regression Analysis)
[빅데이터분석기사] 회귀분석(Regression Analysis)
회귀분석 일반적으로 예측을 목표하는 통계 분석이다. 예측을 하는 방법에 핵심이 되는 개념이 바로 '추세선'이다. 좌표상에서 데이터의 분포와 앞으로의 변화를 가장 잘 설명할 수 있는 하나의
it-utopia.tistory.com
[빅데이터분석기사] 로지스틱 회귀분석(Logistic Regression Analysis)
[빅데이터분석기사] 로지스틱 회귀분석(Logistic Regression Analysis)
로지스틱 회귀 데이터가 어떤 범주에 속할 확률을 0에서 1 사이의 값으로 예측하고, 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류하는 기법이다. 0.5 보다 크면 어떤 사건이 일어
it-utopia.tistory.com
[빅데이터분석기사] 시계열분석(Time-series Analysis)
[빅데이터분석기사] 시계열분석(Time-series Analysis)
시계열분석 시간에 따라 변화되는 자료의 패턴을 밝혀 가까운 미래를 예측하는 방법이다. 시계열분석을 위해서는 시계열 데이터가 준비돼야 한다. 시간의 경과만 한 축(x)을 구성하는 것이 아니
it-utopia.tistory.com
[빅데이터분석기사] 최근접 이웃(K-Nearest Neighbors)
[빅데이터분석기사] 최근접 이웃(K-Nearest Neighbors)
최근접 이웃 알고리즘은 우리가 예측하려고 하는 임의의 데이터와 가장 가까운 데이터 K개를 찾아 다수결에 의해 데이터를 예측하는 방법이다. 위 그림과 같이 두 그룹의 데이터가 있을 때 주어
it-utopia.tistory.com
[빅데이터분석기사] 의사결정나무(Decision Tree)
[빅데이터분석기사] 의사결정나무(Decision Tree)
의사결정나무 일종의 분류 기법이다. 전체 집단을 계속 양분하는 분류기법으로써 분기가 발생하는 포인트(=노드)에는 기준이 되는 질문이 있어 기준 질문에 부합하냐(YES), 부합하지 않느냐(NO)에
it-utopia.tistory.com
'빅데이터분석기사 > 개념' 카테고리의 다른 글
| [빅데이터분석기사] 로지스틱 회귀분석(Logistic Regression Analysis) (0) | 2022.05.27 |
|---|---|
| [빅데이터분석기사] 회귀분석(Regression Analysis) (0) | 2022.05.26 |
| [빅데이터분석기사] 상관분석(Correlation Analysis) (0) | 2022.05.24 |
| [빅데이터분석기사] 분산분석(Analysis of Variance, ANOVA) (0) | 2022.05.23 |
| [빅데이터분석기사] 교차분석(Cross-tabulation Analysis) (0) | 2022.05.22 |