핵심요약
합성곱신경망(CNN)은 인공신경망 모델의 하나로 패턴을 찾아 이미지를 분석하는데 특화된 알고리즘이다. 주요 구성은 크게 합성곱(Convolution) 연산과 풀링(Pooling) 연산으로 나눌 수 있다.
합성곱
원본 이미지와 영상의 패턴을 추출할 수 있는 필터(Filter)를 이용하여 특징을 추출하는 과정이다. 필터는 원본 이미지를 움직이면서(Stribe) 이미지의 특징을 뽑아내는 결과물(Feature Map)을 만든다. 결과물(Feature Map)은 원본 이미지릐 인접한 픽셀 간 연관성 있는 패턴 정보를 잃지 않고 반영할 수 있다.

풀링(Pooling)
합성곱 연산을 통해 나온 결과물에서 대푯값들만 뽑아내는 과정이다. 이미지 패턴 정보를 단순화, 추상화하는 작업으로 생각할 수 있다. 풀링의 종류에는 최대(Max), 최소(Min), 평균(Average) 등 여러 가지가 있는데, 일반적으로 최대 풀링(Max-Pooling)을 사용한다.

인공신경망과 이미지
일반적인 인공신경망은 데이터를 입력층(Input Layer)에 일차원 행렬 형태로 입력한다. 이 경우, 비교적 단순한 구조의 데이터는 문제가 되지 않으나, 분석할 데이터가 이미지와 같이 공간적인 정보를 포함할 때 발생한다. 즉, 이미지 정보는 같은 의미를 갖고 있는 정보일지라도 일부분이 변경되는 경우 일차원 행렬의 관점에서 보면 데이터의 변화가 크기 때문에 일반적인 인공신경망에서는 학습 및 예측의 성능이 제한된다.

필터(Filter)
원본 입력 데이터에 대해 특징값을 뽑기 위해 만들어진 장치이다. 원본이미지와 필터를 합성곱 연상을 시키면 아래 그림과 같이 다양한 특징, 혹은 관점으로 이미지를 인식할 수 있는 결과물이 나온다. 합성곱 신경망에서는 이 필터에 값들이 가중치로서 학습과정에서 데이터에 맞게 변경된다.

앞에서 살펴본 합성곱(Convolution), 풀링(Pooling), 필터(Filter)와 같은 구성요소를 이용하여 합성곱신경망(Convolutional Neural Network)을 어떻게 활용할 수 있을지 살펴보자.
이미지 분류(Image Classification)
입력으로 이미지 정보를 받아서 이미지가 어디에 속할지 분류하는 문제이다. 가령 숫자를 인식하는 문제나 주어진 사진이 개인지 고양이인지 분류하는 문제의 유형이 여기에 해당된다.

위의 그림은 숫자 정보를 받아 0-9까지 숫자를 결과로 예측하는 합성곱신경망의 구조이다. 앞 부분에서 필터(filter)로 합성곱 연산하여 특징맵(Feature Map)을 추출하고 풀링(Polling)연산을 통해 대푯값들만 추출하게 된다. 이 과정을 여러 번 거쳐 생성된 수많은 특징맵(Feature Map)을 인공신경망의 분류 모델에 입력하여 특징맵(Feature Map)의 중요도를 정하는 가중치 조합을 찾아 숫자를 예측한다. 즉, 합성곱신경망(CNN) 분류 모델은 필터(Filter)행렬과 신경망의 가중치 조합을 학습데이터에 맞게 찾아 결과를 예측한다고 볼 수 있다.
이미지 분할(Image Segmentation)
이미지의 관심 부분을 인식하는 문제이다. 자율주행자동차의 주변 환경정보(차도, 인도, 차선 등)를 인식하는 문제나, 의료분야에서 영샹을 판독할 때 병변의 위치를 확인하는 예가 대표적이다. 이미지 분류(Image Classification)가 이미지 전체에 대한 분류 문제였다면 이미지 분할(Image Segmentation)은 픽셀 정보 하나하나에 대한 분류 문제라 할 수 있다.
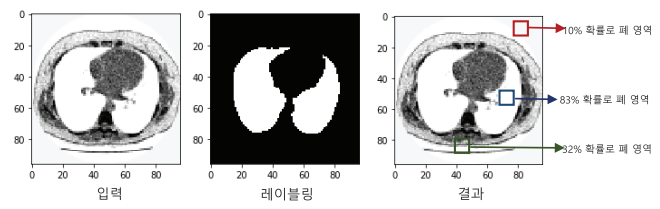
입력 이미지 정보로부터 관심영역(Region of Interest)을 찾기 위해서는 합성곱 연산을 이용해서 특정 패턴을 인식, 식별할 수 있어야 하고 동시에 식별된 부위의 위치정보를 복원(Reconstruction) 할 수 있어야한다. 일반적인 합성곱 신경망은 대푯값을 추출하는 풀링(Pooling) 연산을 통해 원본보다 크기가 작아지기 때문에 아래 그림의 구조처럼 각 부위를 식별하는 동시에 원본 크기의 이미지로 복원하여 부위별로 분할된 예측 결과를 보여준다.

문제정의
부위가 다른 복부(Abdomen) 및 폐(Chest) X-ray 영상을 분류(Classification)
DATASET
- 학습데이터 : 복부(Abdomen) 및 폐(Chest) X-ray 영상 100장
- 시험데이터 : 복부(Abdomen) 및 폐(Chest) X-ray 영상 10장
1) 학습데이터를 이용하여 인공신경망 모델 학습
# 딥러닝 관련 라이브러리
from keras import applications, optimizers
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
from keras.models import Model, Sequential
from keras.layers import *
# 이미지 처리 관련 라이브러리
from skimage.transform import rotate
from skimage import exposure
import matplotlib.pyplot as plt
import numpy as np
import os
2) 학습데이터를 이용하여 인공신경망 모델 학습
BASE_PATH = './dataset/xray_abd_chest'
TRAIN_DATA_PATH = os.path.join(BASE_PATH, 'TRAIN')
VAL_DATA_PATH = os.path.join(BASE_PATH, 'VAL')
TEST_DATA_PATH = os.path.join(BASE_PATH, 'TEST', 'chest1.png')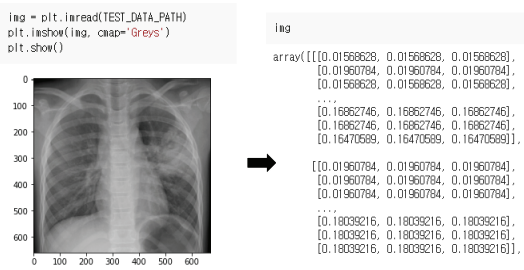
3) 합성곱 신경망을 구성
basemodel = applications.inception_v3.InceptionV3(weight = 'imagenet',
include_top=False,
input_shape=(IMG_HEIGHT, IMG_WIDTH, 3))
model_top = Sequential()
model_top.add(GlobalAveragePooling2D())
model_top.add(Dense(256, activation='relu'))
model_top.add(Dropout(0,5))
model_top.add(Dense(1, activation='sigmoid'))
model = Model(input=basemodel.input, outputs=model_top(basemodel.output))
model.compile(optimizer=Adam(Ir=LEARNING_RATE,
epsilon=1e-8
decay=DECAY_RATE),
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()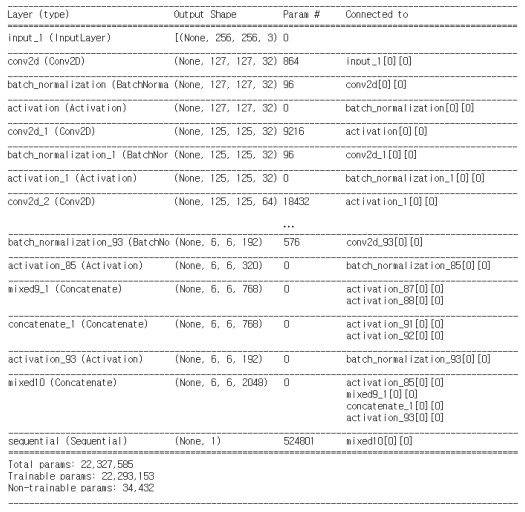
4) 학습데이터를 이용하여 인공신경망 모델 학습

5) 모델 평가
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(epochs, acc, 'b', color='blue', label='Training acc')
plt.plot(epochs, val_acc, 'b', color='red', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
plt.plot(epochs, loss, 'b', color='blue', label='Training loss')
plt.plot(epochs, val_loss, 'b', color='red', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()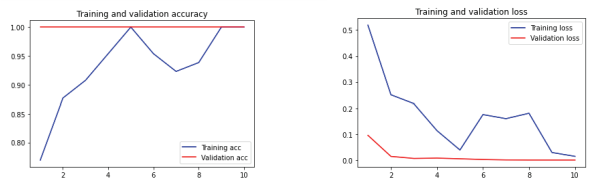
모델이 학습이 잘 되었는지 검증을 하기 위해 훈련 점수 및 손실 함수의 값을 측정하고 그래프로 확인하였다. 시험점수와 학습점수가 학습 횟수가 반복될수록 1에 수렴하고 있고 손실 함수의 값은 반대로 0에 수렴하는 것을 확인할 수 있다.
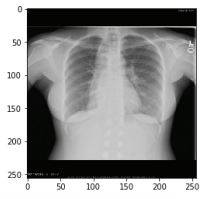
6) 임의의 영상이 복부(abdomen)인지 폐(chest)인지 예측 확인
img1_path = os.path.join(BASE_PATH, 'TEST', 'chest2.png')
img2_path = os.path.join(BASE_PATH, 'TEST', 'abd2.png')
img1 = image.load_img(img1_path, target_size=(IMG_HEIGHT, IMG_WIDTH)
img2 = image.load_img(img2_path, target_size=(IMG_HEIGHT, IMH_WIDTH)
img1 = image.img_to_array(img1)
img1 /= 255.
img1 = img1[np.newaxis, :, :, :]
score1 = model.predict(img1)
print('Predicted: ', 'Chest X-ray' if score < 0.5 else 'Abd X-ray', ' Score:', score1[0, 0])Predicted: Chest X-ray, Score: 5.930332e-05 (예측 값이 약 0.00053 이므로 폐 영상으로 인식)
plt.imshow(img2)
plt.show()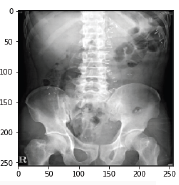
img2 = image.img_to_array(img2)
img2 /= 255.
img2 = img2[np.newaxis, :, :, :]
score2 = model.predict(img2)
print('Predicted: ', 'Chest X-ray' if score2 < 0.5 else 'Abd X-ray', ', Score:', score2[0,0])Predicted: Abd X-ray, Score: 0.98762 (예측 값이 0.988 이므로 복부 영상으로 인식)
함께 보면 좋은 글
[빅데이터분석기사] 순환신경망(Recurrent Neural Network)
[빅데이터분석기사] 순환신경망(Recurrent Neural Network)
핵심요약 순환신경망(Recurrent Neural Network)은 시간 순서가 있는 데이터를 잘 예측하도록 설계된 인공신경망 모델들 중 하나이다. 과거의 신호를 기억할 수 있는 장치(Hidden State)를 두어 입력신호를
it-utopia.tistory.com
[빅데이터분석기사] 연관규칙분석(Association Rule Analysis)
[빅데이터분석기사] 연관규칙분석(Association Rule Analysis)
연관분석 연관분석이란, 대량의 트랜잭션 정보로부터 개별 데이터(변수) 사이에서 연관규칙(x면 y가 발생)을 찾는 것을 말한다. 가령 슈퍼마켓의 구매내역에서 특정 물건의 판매 발생 빈도를 기
it-utopia.tistory.com
[빅데이터분석기사] 교차분석(Cross-tabulation Analysis)
[빅데이터분석기사] 교차분석(Cross-tabulation Analysis)
교차분석 교차분석이란, 비교 대상이 되는 항목들의 빈도를 이용하여 자료 간 관계의 유의성을 파악할 때 사용한다. 주로 '범주형' 자료 간의 관계를 확인하는 데 쓰이며, 전체 비율을 통해 예산
it-utopia.tistory.com
[빅데이터분석기사] 분산분석(Analysis of Variance, ANOVA)
[빅데이터분석기사] 분산분석(Analysis of Variance, ANOVA)
분산분석(=변량분석) 자료 간의 차이를 대조시키는 분석기법이다. 여기서 분산은 평균을 중심으로 데이터가 얼마나 퍼져있는지를 표현하는 통계량이다. 만약 데이터의 퍼짐이 없고 모든 개별
it-utopia.tistory.com
[빅데이터분석기사] 상관분석(Correlation Analysis)
[빅데이터분석기사] 상관분석(Correlation Analysis)
상관분석 상관분석은 x와 y변수 간에 관계가 어떤 선형적인 관계를 갖고 있는지를 파악한다. 두 변수 간의 관계의 강도도 계산할 수 있다. 두 변수가 변하는 패턴이 얼마나 비슷한가를 확인하는
it-utopia.tistory.com
'빅데이터분석기사 > 개념' 카테고리의 다른 글
| [빅데이터분석기사] 순환신경망(Recurrent Neural Network) (0) | 2022.06.16 |
|---|---|
| [빅데이터분석기사] 심층신경망(Deep Neural Network) (0) | 2022.06.10 |
| [빅데이터분석기사] 인공신경망(Artificial Neural Network) (0) | 2022.06.09 |
| [빅데이터분석기사] 군집분석(Clustering Analysis) (0) | 2022.06.08 |
| [빅데이터분석기사] 서포트벡터머신(SVM) (0) | 2022.06.05 |