핵심요약
순환신경망(Recurrent Neural Network)은 시간 순서가 있는 데이터를 잘 예측하도록 설계된 인공신경망 모델들 중 하나이다. 과거의 신호를 기억할 수 있는 장치(Hidden State)를 두어 입력신호를 순환, 반복하는 순환적 구조를 갖고 있어서 시간적 순서 특성을 추출하는데 용이하다.

특징
일반적인 인공신경망이 은닉층을 통해 한꺼번에 가중치 연산이 이루어 지는 것과 비교해서 순환신경망은 이전 데이터의 가중치 연산이 다음 데이터에 일정 부분 영향을 줄 수 있도록 구성되어 있다. 이러한 구조는 시간 순서의 정보가 중요한 데이터에서 이전 데이터를 보고 다음 데이터를 예측하는데 도움을 준다.
순차 데이터(Sequential Data)
순서나 시간이 전체 데이터에서 의미가 있으며 그 순서가 달라질 경우 의미가 크게 변하는 데이터를 말한다. 여기서 단순히 시간적 순서가 있는 데이터를 순차 데이터(Sequential Data)라 부르고 그 중에서도 시간적 간격이 일정한 것을 시계열 데이터(Time Series data)라고 부른다.

활용사례
순환신경망은 순차 데이터(Sequential Data)를 이용하여 다양한 분야에 사용할 수 있다. 순차 데이터의 입력값 혹은 출력값의 크기에 따라 세 가지 유형(One to Many, Many to Many)으로 나누어 구분할 수 있다. 다음 세 가지 유형에 대해 사례별로 살펴보자.
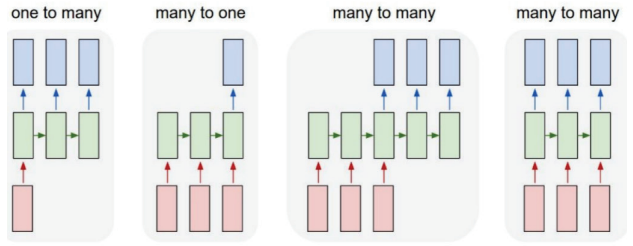
One to Many
고정된 이미지 정보를 해석하여 설명하는 문장을 만드는 이미지 캡션 - Image Caption(Show and Tell, Google)이 대표적인 사례이다. 엄밀하게 이 사례는 두 가지 신경망이 결합된 형태이다. 입력데이터로 들어온 이미지 정보가 합성곱신경망(RNN)이 이것을 입력으로 받아 이미지 정보 의미에 맞게 형태소를 순서대로 배열하여 순서 있는 문장으로 출력하는 것이다.

Many to One
입력값으로 순차 데이터(Sequential Data)가 들어가고 출력값으로 고정된 값을 출력하는 경우를 말한다. 문장을 입력받아 해당 문장이 어떤 감정 혹은 의도를 갖고 있는지 학습하여, 순서 있는 문자 정보에 대해 의도나 감정 분류(classification)하는 문제이다.

Many to Many
입력 및 출력값 모두 순차 데이터로 사용한다. 우리는 Many to Many를 다시 두 가지로 나눌 수 있는데, 하나는 데이터가 입력될 때마다 매 순간(Time-Step)마다 결괏값이 생성되는 경우이며 문장을 입력할때마다 결괏값이 바뀔 수 있는 형태소 분석 등이 여기에 해당이 된다.

그리고 나머지 하나는 입력값으로 모든 순차 데이터가 정해졌을 때 결괏값이 생성되는 번역기와 같은 기능을 사례로 들 수 있다.
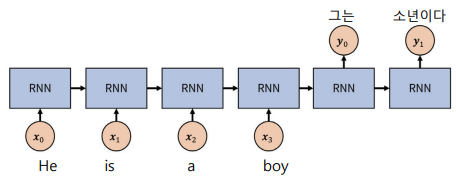
순환신경망(RNN)의 한계와 LSTM(Long Short Term Memory)의 등장

일반적인 순환신경망(RNN)은 위 그림에서 보는 것처럼 입력 X0에 대한 결과 H0를 구한 후, 이 정보를 다음 연산에도 흘려 그 이전 정보를 반복 사용하는 것을 알 수 있다. 이처럼 과거신호를 기억할 수 있는 장치(hidden state)는 순차적인 데이터를 예측할 때 순서 및 시간 정보를 모델에 반영할 수 있는 획기적인 방법이었고 다양한 사례에 활용되면서 합성곱신경망(CNN)과 함께 큰 축을 차지하게 되었다.
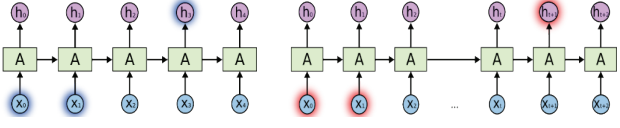
하지만 일반적인 구조의 순환신경망(RNN)은 입력 신호와 출력 신호 사이의 거리가 가까운 경우에 정보를 전달하는 것은 ㄱ별문제가 없지만, 거리가 멀어지면 멀어질수록 정보를 제대로 전달하지 못하는 문제가 발생한다. 순차 데이터 간의 가중치가 서로 동일하기 때문에 거리가 멀수록 기울기 소실문제(Gradient Vanishing Problem)가 더 일어나는 것이다. 이를 순차 데이터 학습에서 긴 기간 의존성 문제(Long term Dependency)라고 하며 이를 해결하기 위해 LSTM(Long Short Term Memory)이 나오게 되었다.
LSTM(Long Short Term Memory)
기본적인 순환신경망(RNN) 구조에 Cell State라는 장치가 더해진 구조를 하고 있다. Cell State를 통해 기억이라는 기능을 좀 더 정교하게 구현할 수 있게 되었는데, 항상 일정한 크기로 이전 정보를 흘려주었던 일반적인 순환신경망(RNN)과 달리 이전 순번의 데이터들 중에서 기억해야 할 것은 더 오래 기억하고 별로 의미 없는 것들은 빨리 잊어버리는 역할을 하는 것이다.
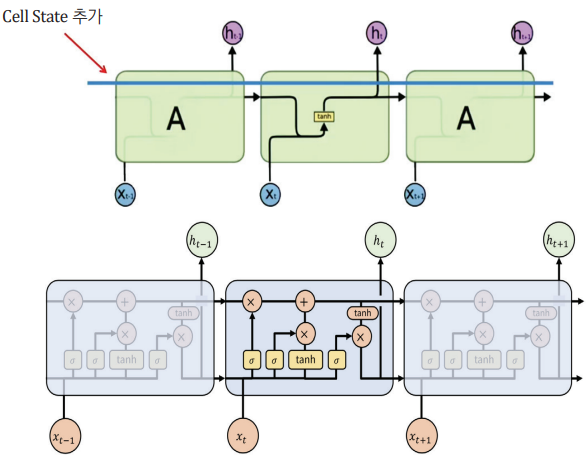
Cell State를 새로 추가 하면서 기능별로 LSTM을 정리하면 다음과 같다.
1. 이전 Cell State에서 불필요한 정보를 제거
2. 이전 Cell State와 현재 입력값의 중요도를 고려해 Cell State를 생성
3. 이전 및 현재 Cell State를 이용하여 Hidden State를 만든다.
4. 현재 Cell State와 Hidden State를 다음 순서의 신경망에 전달한다.
문제정의
접수일자별 청구 데이터를 통해 앞으로 들어올 청구금액을 예측
DATASET DW
데이터베이스에서 본원 심사 청구서를 접수일자(1996.2~2021.5)별로 요양급여총액, 청구금액총액, 본임부담금 총액, 진료비총액 등 7개의 특성값으로 총 7,518건 추출하였다. 이중에서 보험자 구분은 '건강보험'이고, 청구구분은 '일반청구'를 대상으로 하였다.
1. 데이터 확인하기
2. 일자 별 총 청구금액 추이 그래프
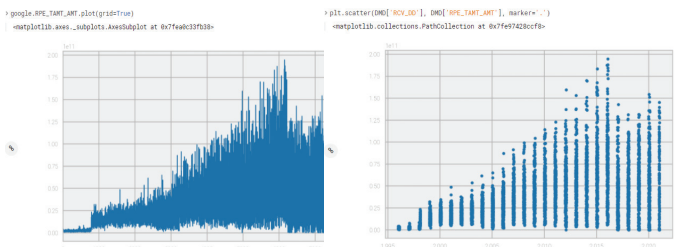
전체적으로 늘었다 줄었다를 반복하면서 1996년부터 서서히 증가하다가 2015, 2016년에 최고점을 찍고 최근 3년간은 조금 줄어든 것을 확인할 수 있다.
3. 학습데이터 정규화
from sklearn.preprocessing import MinMaxScaler
DMD.sort_index(ascending=False).reset_index(drop=True)
scaler = MinMaxScaler()
scale_cols = ['DMD_TOT_CNT', 'SLF_BRDN_TOT_AMT', 'RPE_TAMT_AMT', 'DMD_SPAMT_TOT_AMT', 'HNDP_FND_TOT_AMT', 'DMD_TOT_AMT', 'DAMT_TOT_AMT']
df_scaled = scaler.fit_transform(DMD[scale_cols])
df_scaled = pd.DataFrame(df_scaled)
df_scaled.columns = scale_cols
df_scaled각 변수인 청구 총액, 진료비 총액, 본인 부담금 총액 등은 변수별로 다른 범위를 갖고있는 변수이다. 따라서 학습 시 모든 값을 0에서 1사이의 값으로 변경(rescale)해주었다.
4. 데이터 전처리
TEST_SIZE = 75
WINDOWS_SIZE = 30
train = df_scaled[:-TEST_SIZE]
test = df_scaled[-TEST_SIZE:]
def make_dataset(data, label, windows_size):
feature_list = []
label_list = []
for i in range(len(data) - windows_size):
feature_list.append(np.array(data.iloc[i+windows_size]))
label_list.append(np.array(label.iloc[i+windows_size]))
return np.array(feature_list), np.array(label_list)
from sklearn.model_selection import train_test_split
feature_cols = ['DMD_TOT_CNT', 'RPE_TAMT_AMT', 'DMD_SPANT_TOT_AMT', 'HNDP_FND_TOT_AMT', 'DMD_TOT_AMT', 'DAMT_TOT_AMT']
label_cols = ['DMD_TOT_ANT']
train_feature = train[feature_cols]
train_label = train[label_cols]
train_feature, train_label = make_dataset(train_feature, train_label, WINDOWS_SIZE)
x_train, x_valid, y_train, y_valid = train_test_split(train_feature, train_label, test_size=0.2)
TEST_SIZE와 WINDOW_SIZE 값을 각각 70일과 30일로 설정하였다. 여기서 TEST_SIZE는 70일치를 예측하겠다는 의미이며, WINDOW_SIZE는 과거 30일치를 기준으로 다음 번에 들어올 청구 총 금액을 예측하겠다는 의미이다. 학습 및 검증 데이터 분리는 8:2로 구성하였다.
5. 모델 생성 및 학습
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras.layers import LSTM
model = Sequential()
model.add(LSTM(45,
input_shape=(train_feature.shape[1], train_feature[2]),
activation='relu',
return_sequences=False)
)
model.add(Dense(1))
model.summary()
model.compile(loss='mean_squared_error', optimizer='adam')
early_stop = EarlyStopping(monitor='val_loss', patience=5)
model_path = './'
filename = os.path.join(model_path, 'tmp_checkpoint.h5')
checkpoint = ModelCheckpoint(filename, monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
history = model.fit(x_train, y_train, epochs=200, batch_size=16, validation_data=(x_valid, y_valid), callbacks=[early_stop, checkpoint])
메모리 셀의 개수를 16개, 입력값에 30일치, 하루에 6개의 특성값을 입력값으로 받아 하나의 결과(청구 총 금액)를 예측하는 Many-to-One LSTM을 구성하였다. 오차함수로 회귀 문제에 사용되는 오차평균제곱 함수를 사용하였고, 최적화 함수로는 'adam'을 사용하여 200번 반복을 하면서 검증 오차가 향상될 때까지 반복 학습을 진행하였다.
6. 결과

28번째 반복 학습 만에 오차함수의 값이 0.00868에서 학습이 더 진행되지 않은 채 종료되었다. 학습 데이터를 모델을 넣어 확인한 결과와 테스트 데이터를 통해 확인한 결과는 다음과 같다.
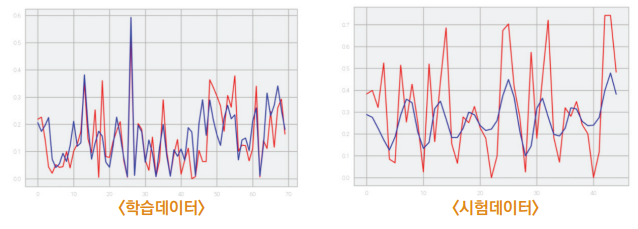
학습에 사용한 일자별 청구 데이터가 시간 순서를 기반으로 하지만 데이터가 앞뒤 시간 순서 간 관련성이 크지 않기 때문에 구체적인 금액보다 주기나 패텅 위주로 예측하는 것을 확인할 수 있었다.
함께 보면 좋은 글
[빅데이터분석기사] 연관규칙분석(Association Rule Analysis)
[빅데이터분석기사] 연관규칙분석(Association Rule Analysis)
연관분석 연관분석이란, 대량의 트랜잭션 정보로부터 개별 데이터(변수) 사이에서 연관규칙(x면 y가 발생)을 찾는 것을 말한다. 가령 슈퍼마켓의 구매내역에서 특정 물건의 판매 발생 빈도를 기
it-utopia.tistory.com
[빅데이터분석기사] 교차분석(Cross-tabulation Analysis)
[빅데이터분석기사] 교차분석(Cross-tabulation Analysis)
교차분석 교차분석이란, 비교 대상이 되는 항목들의 빈도를 이용하여 자료 간 관계의 유의성을 파악할 때 사용한다. 주로 '범주형' 자료 간의 관계를 확인하는 데 쓰이며, 전체 비율을 통해 예산
it-utopia.tistory.com
[빅데이터분석기사] 분산분석(Analysis of Variance, ANOVA)
[빅데이터분석기사] 분산분석(Analysis of Variance, ANOVA)
분산분석(=변량분석) 자료 간의 차이를 대조시키는 분석기법이다. 여기서 분산은 평균을 중심으로 데이터가 얼마나 퍼져있는지를 표현하는 통계량이다. 만약 데이터의 퍼짐이 없고 모든 개별
it-utopia.tistory.com
[빅데이터분석기사] 상관분석(Correlation Analysis)
[빅데이터분석기사] 상관분석(Correlation Analysis)
상관분석 상관분석은 x와 y변수 간에 관계가 어떤 선형적인 관계를 갖고 있는지를 파악한다. 두 변수 간의 관계의 강도도 계산할 수 있다. 두 변수가 변하는 패턴이 얼마나 비슷한가를 확인하는
it-utopia.tistory.com
[빅데이터분석기사] 주성분분석(Principal Component Analysis)
[빅데이터분석기사] 주성분분석(Principal Component Analysis)
주성분분석 여러 특성(feature) 가운데 대표 특성을 찾아 분석하는 방식으로, 대표 특성의 선별은 자료의 차원을 고차원에서 하위 차원으로 축소하는(차원축소) 기법을 활용한다. 차원축소기법에
it-utopia.tistory.com
'빅데이터분석기사 > 개념' 카테고리의 다른 글
| [빅데이터분석기사] 합성곱신경망(Convolutional Neural Network) (0) | 2022.06.15 |
|---|---|
| [빅데이터분석기사] 심층신경망(Deep Neural Network) (0) | 2022.06.10 |
| [빅데이터분석기사] 인공신경망(Artificial Neural Network) (0) | 2022.06.09 |
| [빅데이터분석기사] 군집분석(Clustering Analysis) (0) | 2022.06.08 |
| [빅데이터분석기사] 서포트벡터머신(SVM) (0) | 2022.06.05 |