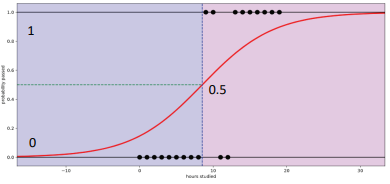
의사결정나무 일종의 분류 기법이다. 전체 집단을 계속 양분하는 분류기법으로써 분기가 발생하는 포인트(=노드)에는 기준이 되는 질문이 있어 기준 질문에 부합하냐(YES), 부합하지 않느냐(NO)에 따라 노드 이동의 방향이 결정된다. 의사결정나무 모형은 분류(classification)와 회귀예측(regression) 모두 가능한 알고리즘이다. 분류나무 모형은 불연속적(이산형 자료)인 값을 예측한다. 예를 들어 분류 모델은 다음과 같은 질문에 대한 답을 예측한다. '수신된 이메일이 스팸인가 아닌가?', '이 사진이 강아지인가 고양이인가 또는 햄스터인가?'와 같은 질문에 답을 내기 적합한 비지도 분류 알고리즘 모형이다. 한편 회귀분석의 한 갈래인 회귀나무 모형은 연속적인 값을 예측한다. 예를 들어 회귀 모델은..