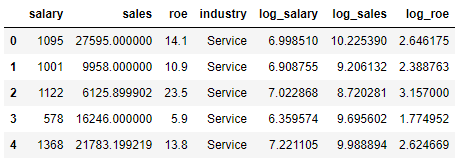
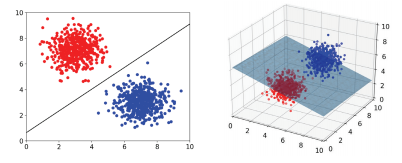
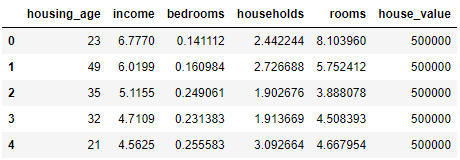
핵심요약 인공신경망(ANN)은 기계학습과 인지과학 분야에서 고안한 학습 알고리즘이다. 신경세포의 신호 전달체계를 모방한 인공뉴런(노드)이 학습을 통해 결합 세기를 변화시켜 문제를 해결하는 모델 전반을 가리킨다. 인공신경망의 시작, 퍼셉트론 퍼셉트론은 신경세포 뉴런들이 신호, 자극 등을 받아 어떠한 임계값(threshold)을 넘어서면 그 결고를 전달하는 신경세포의 신호 전달 과정을 착안하여 만들어졌다. 이를 수학적인 기호로 모델링 한 것이 퍼셉트론인데, 퍼셉트론은 각각의 가중치의 크기를 적절히 조절하여 입력 신호이 크기를 정한다. 입력 신호들의 합에 활성화 함수를 거쳐 나온 결괏값을 전달함으로써 원하는 결괏값을 얻는 방식으로 동작한다. 아래 그림은 단층 퍼셉트론으로 AND, OR, NAND와 같은 비교적..